こんにちは、アイダです。みなさんの今年の漢字はなんですか?私は「梨」です。これまでは皮をむくのが手間だったので滅多に食べていなかったのですが、皮むき器と8等分カッターを購入したら、苦労なく食べられることに気づきました。旬が過ぎたのでいまはりんご生活です。
さて、今回は Japan Tableau User Group(JTUG)の冬の総会で、DX共創センターの K さんとグループビジネス推進ユニットの T さんが紹介した内容の詳細解説、後半戦です。残り半分いっちゃってください!
第一部ご登壇🎉
— Japan Tableau User Group(JTUG) (@jp_tug) 2021年12月5日
ゴールドスポンサーのご紹介②🌟
「株式会社インテージテクノスフィア」
コレスポンデンス分析をテーマにしたセッションをお届け頂きます✨
ポジショニング確認等に用いる分析手法ですが、実践したくなるテーマなのではないでしょうか😳
お楽しみに!#JTUG冬https://t.co/DMqs7ox2zW
はじめに
前回の記事「環境設定編」では、TabPy の設定、TabPy を使うための設定についてご紹介しました。
今回は TabPy 連携を用いて、どのようにコレスポンデンス分析をワークシートで実現するかについて紹介していきます。 Tableau の計算フィールドや Python スクリプトも登場しますが、がんばってついてきてください!
Tableau - TabPy のやりとり
計算フィールドに Python スクリプトを入力することで、TabPy での処理内容を定義します。 Tableau の計算フィールドには SCRIPT 関数というものがあり、返したい値によって以下を使い分けます。
- SCRIPT_BOOL:論理値
- SCRIPT_INT:整数値
- SCRIPT_REAL:実数値
- SCRIPT_STR:文字列
1回のやりとりでバシッと結果を取得したいところですが、
スコアは実数値、表示用のラベルは文字列なので、TabPy サーバーとのやりとりが複数回発生するのは避けることができなそうです。

Tableau のデータソースにはアンケート回答データを読み込ませていますが、 TabPy へ渡すデータは以下のようなクロス集計です。
データ:株式会社インテージが保有する自動車に関する調査「Car-kit®」
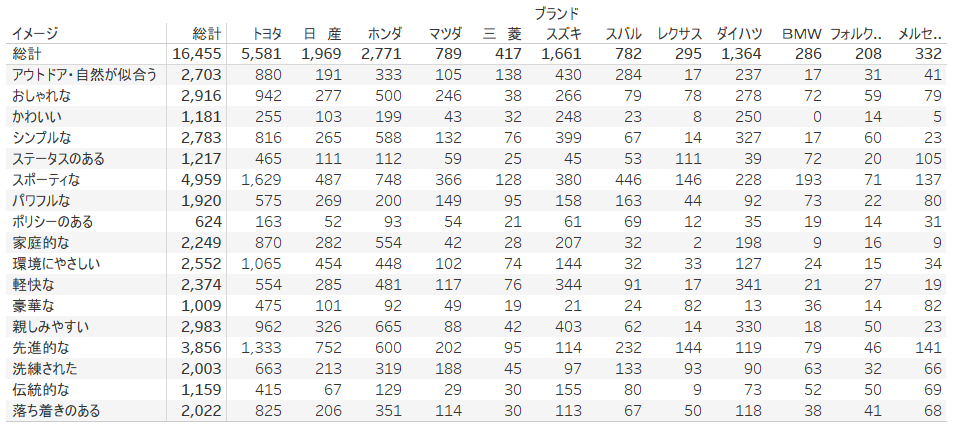
計算フィールド解説
計算フィールドとしては以下の4つを作成します。
- 第1軸スコア
- 第2軸スコア
- ラベル
- 表側・表頭判定
第1軸スコア
計算フィールドの中身はこちらです。
SCRIPT_REAL("
import mca
import pandas as pd
# data
input_values = _arg1
# ans(image,etc...)
input_rows = _arg2
# loop(brand,etc...)
input_cols = _arg3
# 3項目ごとになっているため、転置してレコードごとに変換
data = [list(x) for x in zip(*[input_values,input_rows,input_cols])]
pdata = pd.DataFrame(data)
#各列の名称を定義input_valuesは数値
pdata.columns = ['input_values', 'input_rows', 'input_cols']
# 行にブランド、列にブランドイメーシでクロス集計(値は集計済みのため並び替え)
pdata = pd.pivot_table(pdata, values='input_values', index='input_rows', columns='input_cols', aggfunc='sum')
# null(NaN)など無効値を0に変換
pdata = pdata.fillna(0)
# コレスポンデンス集計
mca_counts = mca.MCA(pdata, benzecri=False, TOL=1e-8)
out_rows = mca_counts.fs_r(N=2)# 表側データ
out_cols = mca_counts.fs_c(N=2)# 表頭データ
# 第1軸スコアを取得
xrows = out_rows[:, 0]
xcols = out_cols[:, 0]
out_list = (xrows).tolist()+(xcols).tolist()
return out_list+[None]*(len(input_values)-len(out_list))
",[回答数],ATTR([イメージ]),ATTR([ブランド]))
すこし詳しく見ていきましょう。
まず、Python スクリプトの引数として、クロス集計の回答数、表側ラベル、表頭ラベルに該当するものを渡します。

第1引数の "回答数" は1次元配列の形で渡されるので、クロス集計の形に変換します。

MCAライブラリを使ってコレスポンデンス分析を実行。

実行結果から、第1軸のスコアを返します。
このとき、表側と表頭のスコアを連結して1つの配列としてから返します。

第2軸スコア
計算フィールドの中身は第1軸スコアのものとほとんど同じです。 異なるのは返す値を取得する部分だけです。
# Y座標の取得 yrows = out_rows[:, 1] ycols = out_cols[:, 1] out_list = (yrows).tolist()+(ycols).tolist() return out_list+[None]*(len(input_values)-len(out_list))
ラベル
ラベル表示用の文字列を取得したいだけではありますが、 スコアの配列と揃えるために、クロス集計の形に変換したデータフレームからラベルを取得しています。
SCRIPT_STR("
import mca
import pandas as pd
input_values = _arg1
input_rows = _arg2
input_cols = _arg3
#3項目ごとになっているため、転置してレコードごとに変換
data = [list(x) for x in zip(*[input_values,input_rows,input_cols])]
pdata = pd.DataFrame(data)
#各列の名称を定義input_valuesは数値
pdata.columns = ['input_values', 'input_rows', 'input_cols']
#行にブランド、列にブランドイメーシでクロス集計(値は集計済みのため並び替え)
pdata = pd.pivot_table(pdata, values='input_values', index='input_rows', columns='input_cols', aggfunc='sum')
#null(NaN)など無効値を0に変換
pdata = pdata.fillna(0)
labelsIdx = pdata.index.values.tolist()
labelsCol = pdata.columns.values.tolist()
out_list = labelsIdx+labelsCol
return out_list+[None]*(len(input_values)-len(out_list))
",[回答数],ATTR([イメージ]),ATTR([ブランド]))
表側・表頭判定
計算フィールド:ラベルの値によって、"イメージ" なのか "ブランド" なのかを判定します。 CASE 文でも IF 文でもいいでしょう。
ワークシート作成解説
計算フィールドが用意できたら、ワークシートを作成します。
ここでひとつ大事な Tips を。 SCRIPT 関数は "表計算" 扱いです。今回は "表計算" の方向をひとつずつ指定しなければならず、かつそのあいだはエラーが発生し続けます。 これを回避するために、[自動更新の一時停止] を設定しておきましょう。
では、いきます。
まずは集計単位となる [イメージ] と [ブランド] を 詳細 にセットします。
次に 列に [第1軸スコア] を、行に [第2軸スコア] を、ラベルに [ラベル] をセットします。
表計算の方向はすべて、特定のディメンション [イメージ] [ブランド] とします。

ここまでできたら、[自動更新の再開] を設定します。
最後に表側ラベルと表頭ラベルを識別するために 色 に [表側・表頭判定] をセットします。

あとは細かい部分を整えていけば完成です。

おわりに
いかがでしたでしょうか。 環境設定や Python スクリプトも必要になるので、"お手軽" とまではいきませんが、 Tableau で自由度の高いコレスポンデンス分析を実現することができました。
しかし、TabPy サーバーで同じ分析を複数回実行せざるをえないのが悩ましいです。 なにかいい解決策があれば教えてください。
この内容は JTUG 冬の総会 2021 でご紹介したものです。 YouTube に動画もありますのでぜひご覧ください。