こんにちは、アイダです。 膨大なデータ処理を高速で実行するクラウド型データウェアハウス(DHW)として注目を集めている Snowflake。 より高速化するため、クラスタリングキーのチューニングについて担当したエンジニアのHが投稿します。 それではHさんどうぞ。

はじめに
インテージテクノスフィアのHです。
現在、全国のスーパーマーケットやコンビニなど、小売店の販売データの集計システムを開発しています。
今回は我々のシステムの集計基盤であるSnowflakeのクラスタリングキーを用いたクエリチューニングや使い所について、 よくありそうな例を用いて深堀りしていきたいと思います。
Snowflakeではマイクロパーティションとナチュラルデータクラスタリングが自動的に適用されるため、ユーザー側は特に意識せずとも爆速で集計・分析できるのですが、 業務要件や頻出集計・分析によってはクラスタリングキーを指定するとより速くなるかもよ、というお話です。
マイクロパーティションやデータクラスタリングについては以下を参照ください。
マイクロパーティションとデータクラスタリング
よくありそうな集計の流れ
DWHの設計としてよくありそうな、とある販売実績データをディメンションテーブル(青)、商品マスタや販売店マスタをファクトテーブル(赤)とした集計を例としてみます。
販売実績テーブルは日単位で常にレコードが追加されており、3年分で数十億レコード程度が現時点で格納されているとしましょう。
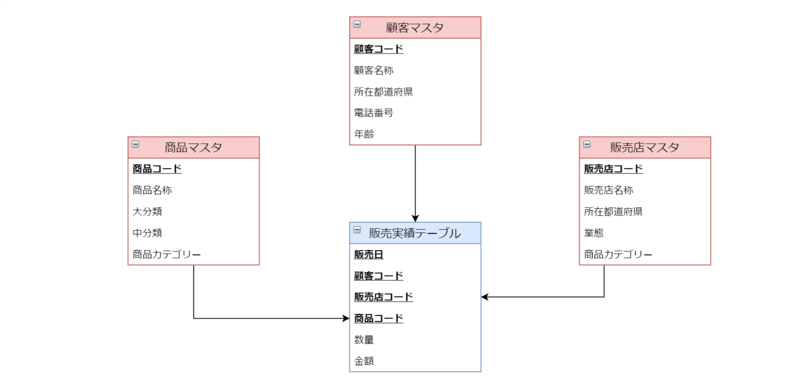
これらのデータから、例えばとある1つの商品カテゴリーにおける2年間の商品ごとの販売金額の合計を日単位で時系列に集計したいときは、 こんなクエリを書くかと思います。
WITH 商品 as ( SELECT 商品コード , 商品名称 FROM 商品マスタ WHERE 商品カテゴリー = '1' ) SELECT 販売実績テーブル.販売日 , 販売実績テーブル.商品コード , 商品.商品名称 , SUM(販売実績テーブル.金額) as 金額計 FROM 販売実績テーブル JOIN 商品 ON (商品コード) WHERE 販売実績テーブル.販売日 BETWEEN '2018-01-01' AND '2020-12-31' GROUP BY 販売実績テーブル.販売日 , 販売実績テーブル.商品コード , 商品.商品名称 ;
まあ、これだけでもSnowflakeはかなり速く結果を返してくれるとは思います。
クラスタリングキーを定義することについてのメリット
我々はSnowflakeの掲げるニアゼロメンテナンスによって、何も考えずにマイクロパーティションやデータクラスタリングの恩恵を得られます。
ただし、何かしらの要件・要因により思ったようなレスポンスをSnowflakeから得られないときは、
クラスタリングキーを定義することで、クエリのスキャン効率が向上したり列圧縮が向上したりと全体的にクエリの性能向上が期待できます。
・フィルタリング述語と一致しないデータをスキップすることにより、クエリのスキャン効率が向上しました。
・クラスタリングのないテーブルよりも列圧縮が向上します。これは、他の列がクラスタリングキーを構成する列と強く相関している場合に特に当てはまります。
・テーブルでキーが定義された後、キーをドロップまたは変更することを選択しない限り、追加の管理は必要ありません。(最適なクラスタリングを保証するための)テーブル内の行に対する今後のすべてのメンテナンスは、Snowflakeによって自動的に実行されます。
https://docs.snowflake.com/ja/user-guide/tables-clustering-keys.html#what-is-a-clustering-key
クラスタリングキーを設定する際は、クラスタリングキーの定義は全てのテーブルに当てはまることではないことや、自動クラスタリングによるコストなど注意は必要です。
クラスタリングキーを設定するときの優先順としてはSnowflakeでは以下を推奨しています。
1.選択フィルターで最もアクティブに使用されるクラスタ列。日付ベースのクエリに関係する多くのファクトテーブル(例:WHERE invoice_date > x AND 請求日 <= y」)の場合、日付列を選択することをお勧めします。イベントテーブルでは、多数の異なるイベントタイプがある場合にイベントタイプが適切な選択になる場合があります。(テーブルに含まれるイベントタイプが少数の場合は、クラスタリングキーとしてイベント列を選択する前に、以下のカーディナリティに関するコメントを参照してください。)
2.追加のクラスタキーの余地がある場合は、結合述語で頻繁に使用される列、例:「FROM table1 JOIN table2 ON table2.column_A = table1.column_B」を検討してください。
クラスタリングキーを選択するための戦略
日付でクラスタキー設定しておくみたいなよくあるDWHのお作法は、テーブルスキャンを少なくするという意味ではとても大事だと思います。
問題は上記の 2. です。。
2.追加のクラスタキーの余地がある場合は、結合述語で頻繁に使用される列
クラスタリングキーを選択するための戦略
ここの記述、先程のよくあるスタースキーマの集計例でいうと
WITH 商品 as ( SELECT 商品コード , 商品名称 FROM 商品マスタ WHERE 商品カテゴリー = '1' ) SELECT 販売実績テーブル.販売日 , 販売実績テーブル.商品コード , 商品.商品名称 , SUM(販売実績テーブル.金額) as 金額計 FROM 販売実績テーブル JOIN 商品 ON (商品コード) WHERE 販売実績テーブル.販売日 BETWEEN '2018-01-01' AND '2020-12-31' GROUP BY 販売実績テーブル.販売日 , 販売実績テーブル.商品コード , 商品.商品名称 ;
ディメンションテーブルである販売実績テーブルのクラスタリングキーを(販売日, 商品コード)にすると、 商品マスタを結合するだけで、それらの商品コードの出現レコードによってもうまくプルーニングしてくれるっていうことになります。 (スター型変換の動的プルーニングっていうやつでしょうか?)
要するに、巨大なディメンションテーブルのスキャンが日付単位のフィルターをしただけでもそれなりにコストがかかるなら、
常に結合を想定しているファクトテーブルのキーもクラスタリングキーに設定しておけば、
ディメンションテーブルへのスキャンを格段に速くできる可能性を秘めているということになります。
しかも、上記クエリを全く変えることなく性能向上が可能というおまけ付き。
手元のダミーデータで検証したところ、やはりプルーニングに差が出てくるようです。
体感で集計速度が2/3程度になりました。
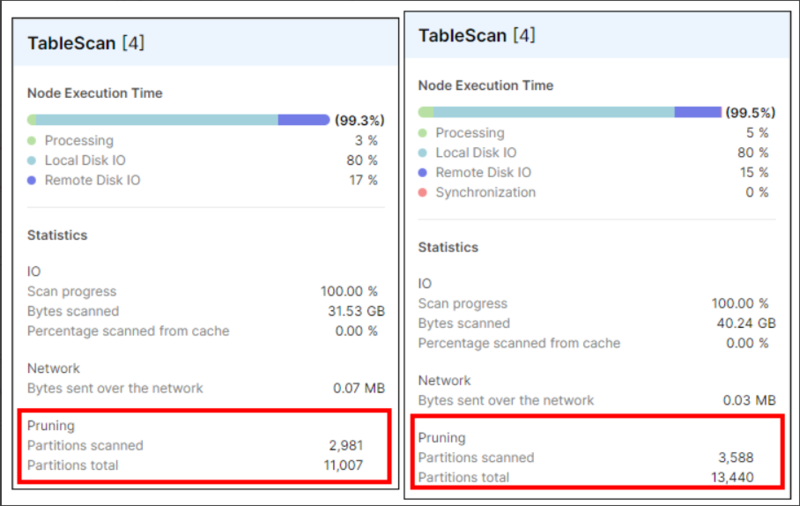
左:販売日、商品コードでクラスタリングキーした定義した場合
右:販売日のみでクラスタリングキーを定義した場合
なにかとても当たり前のようなことを書いているのですが、 よくあるDWHのお作法として、テーブルスキャンをフィルタリング述語で行うっていうことは把握していても 結合述語でもプルーニングしてくれるよって把握できていない方も多いのではないでしょうか?
ただし、要件やらデータ量やらにカーディナリティによっても考え方かなり変わると思いますので、 各々の特性にあったチューニングをする際の一助となればと思います。
以上、Snowflakeのクラスタリングキーに関する考察でした。
何かのご参考になれば、幸いです。