こんにちはアイダです。2020年11月のイベント「DATA CLOUD SUMMIT 2020」(Snowflake社主催) にて、Snowflake導入によるデータ基盤開発の成功事例をお話しました。 今回はプロジェクトに関わった技術者Aさんが、Snowflakeの注目機能であるCloneを使った、データ更新のお話です。それではAさんどうぞ!

はじめに
インテージテクノスフィアのAです。 現在、全国のスーパーマーケットやコンビニなど、小売店の販売データの集計システムを開発しています。 今回はSnowflakeのCloneという機能を使ったデータ更新について紹介します。
集計システムの簡単な流れとしては以下の通りです。 集計基盤としてSnowflakeを採用しています。
1.集計の条件が記載されたリクエストのJsonをAWS ECSへ
2.ECSでクエリへ変換
3.ECSからSnowflakeでクエリ実行

データ更新に関する要件
小売店の販売データは日々更新されます。 基幹系システムでクレンジング済のデータを定期的にSnowflakeへ取り込んでいます。 取り込みの頻度は1日に1~2回程度です。 取り込まれたデータは定時で公開する必要があります。 つまり、リアルタイムで更新する必要ありません。
まとまったデータを定期的に取り込むため、継続的なデータロードを叶えるSnowpipeではなく、 Copyコマンドによる一括ロードを採用しました。
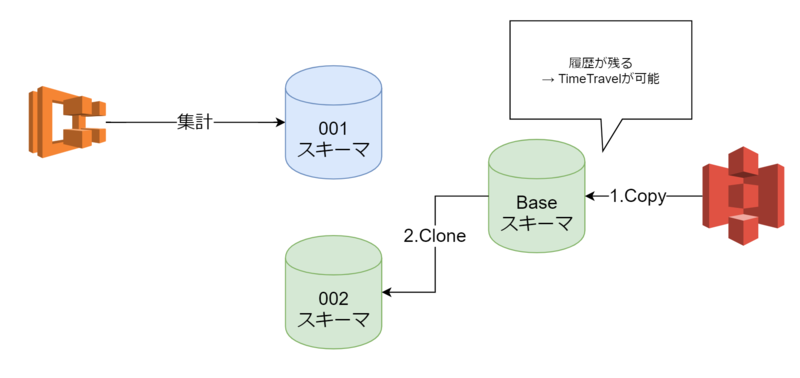
また、誤ったデータをロードした際の対策としてTimeTravelという機能(後述)を使うために 複数スキーマを用意し、Copy後にClone(後述)するようにしました。
Cloneを使ったデータ更新
上記の要件を満たすため、私たちはSnowflakeで3つのスキーマを用意しました。 実際にS3からデータを取り込むBaseスキーマ、BaseからCloneされ、実際に集計に利用される001、002スキーマです。
基幹系システムからデータ更新のリクエストがあった場合、以下の流れでデータ更新します。
1.基幹系システムによってS3に配置されたデータをBaseスキーマへCopy
2.Baseスキーマから集計に使われていないスキーマへClone
Cloneとはコピーを作成することです。
スキーマをCloneすると、同じスキーマが複製されます。
Snowflakeは論理テーブルと物理ストレージが分離されており、
Cloneの場合、データが物理的にはコピーされず、同じデータを参照します。
ZeroCopyCloningと呼ばれ、論理テーブルのコピーだけであるため、Clone自体も高速です。
そのため、定時のデータ公開までの時間的猶予が生まれるのもうれしいところです。
(ちなみにCloneですが、本番データを開発環境へ持ってくる場合などにも、さっと使えるので非常に使い勝手がいいです。)
TimeTravelを利用したいという話がありましたが、Clone先のスキーマは履歴が残らず、TimeTravelできません。
そこでBaseスキーマを用意することで、履歴が残り、TimeTravelの利用を可能にしました。
TimeTravelとはある一定の期間内であれば、任意の時点でのデータにアクセスすることができる機能です。
つまり、データをうっかり変更や削除してしまっても、以前の状態のデータにアクセスすることができます。
Snowflakeがイミュータブルなオブジェクトを採用していることによって可能になった特徴的な機能です。
万が一、間違ったデータをCopyしたり、001、002スキーマがなくなったとしてもBaseスキーマをTimeTravelし、
Cloneすれば、更新前に戻すことが可能です。
CopyとCloneが終わり、集計に使われていない、スタンバイのスキーマ(下図でいうと002スキーマ)の更新が終わってしまえば、 あとは定時で集計に利用するスキーマの情報を切り替えることで、それを参照しているECSはデータ更新済のスキーマで集計できます。
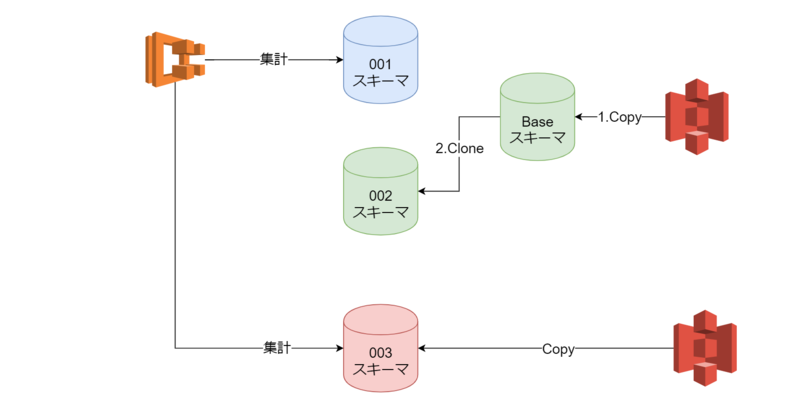
データによっては随時更新するものがありました。
我々が扱っている、このタイプのデータは、ある程度まとまっているデータであること、多少加工が必要であることから、
Snowflakeで簡単な加工をしてから、集計に利用しているスキーマに直接、Copyして更新しています。
以上、 Snowflakeのアーキテクチャだからこその機能である、ZeroCopyCloning、TimeTravelを活用した データ更新の紹介でした。
何かのご参考になれば、幸いです。