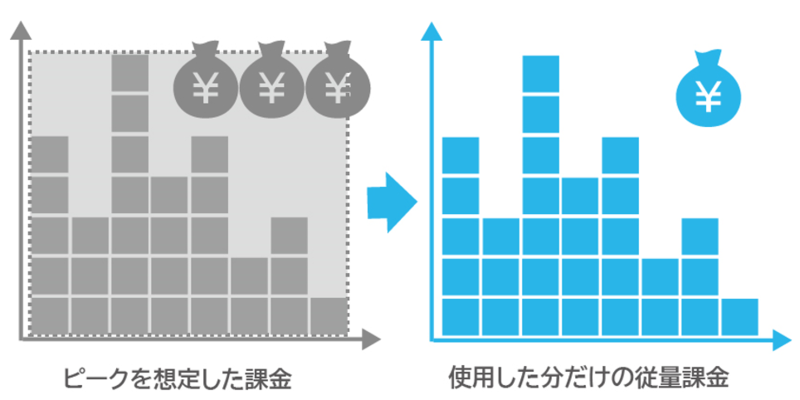
こんにちは、アイダです。 Snowflakeは従量課金制のシステム。使った分だけ秒単位で課金されます。 エンジニアのSは、オンラインの集計システムにてピーク/ボトムに応じたリソースの調整を担当。工夫により費用を抑えることに成功しました。 今回は、Lambdaを使ったSnowflakeのリサイズについてSさんが投稿します!
はじめに
インテージテクノスフィアのSです。 現在、全国のスーパーマーケットやコンビニなど、小売店の販売データの集計システムを開発しています。 今回はSnowflakeのリサイズをLambdaで実装してみたのでご紹介します。
集計システムについて
まず、初めに開発している集計システムの概要/特徴 を踏まえて、実装に至った経緯を説明します。
処理フロー
- 提供系からjson形式で集計リクエストを受信
- ECS内でクエリに変換
- Snowflakeでクエリ実行
特徴
- Snowflake上で時系列の小売店の販売データを保持している(膨大なデータ量)
- 定期的にバッチ処理で追加されたデータの公開を行う
- データ公開日の朝に集計が集中する
オンラインの集計システムなので常時稼働させておく必要はあるものの 日や時間帯でアクセス数にバラつきがあるため、負荷の少ない時は最小限 のリソースで起動しておき、高負荷時にはリソースを増強するという ピーク/ボトムに応じたリソースの調整が必要でした。
アーキテクチャ
内部の仕組みはこちら。
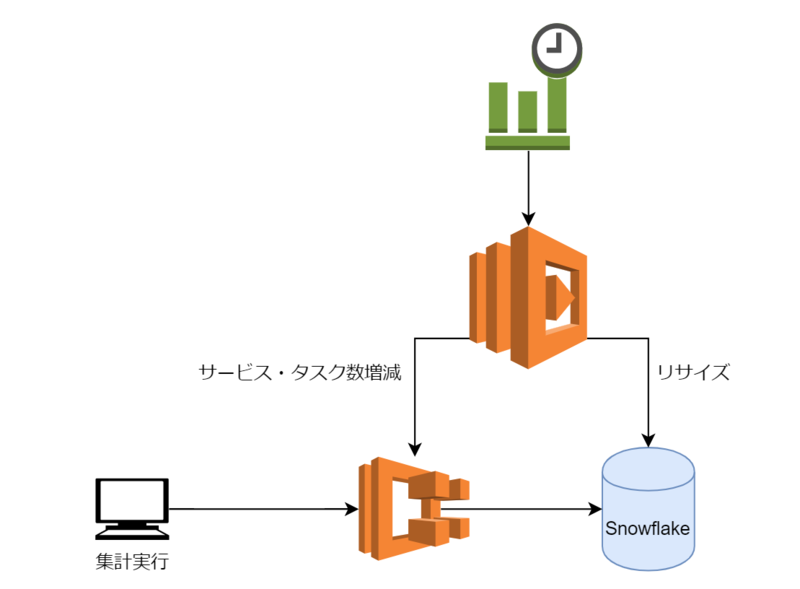
リサイズの処理フロー
1.CloudWatchEventのcronでLambdaを定期実行
リサイズを実施するLambdaをCloudWatchEventでトリガーする
2.LambdaでECS、Snowflake ウェアハウスのリサイズ
・外部サービスでECSのサービス/タスク数、ウェアハウスのサイズ及びクラスター数
のmin/maxの設定値を時間帯ごとに保持
・設定値に従ってSFのウェアハウスサイズをLarge→X-Large、クラスタ数(max)を
3→4、ECSのタスク数を1→2へ変更
ウェアハウスサイズ変更は、DATA CLOUD SUMMIT 2020で発表された「Query
Acceleration Service」で将来的に自動化されるかもしれません
■処理前
Snowflake

ECS

■処理後
Snowflake

ECS

リサイズ後は、auto resume/suspendというSnowflakeの機能で アクセスに応じて自動的にウェアハウスを起動/停止してくれます。
初回アクセス時から最大のパフォーマンスを出したいなら・・・
auto resumeでウェアハウスを自動起動できますが、
立ち上げるクラスタ数が増えるにつれて、起動までに
時間が掛かりクエリがキュー待ちになります。
この待ち時間が許容できない場合や初回アクセス時から最大のパフォーマンスを出したい場合には事前にウェアハウス起動&キャッシュをするという方法もあります。
Snowflakeはコンピュートとストレージを分離したアーキテクチャであり、S3上にデータを保持しています。
そのため、初回アクセス時はS3からのデータ取得でremote I/Oが発生し時間が掛かってしまいます。
※一度取得したデータはクラスター内にキャッシュされるため、2回目以降は高速になります。
上記の通り、ピーク/ボトムに合わせたウェアハウスのスペック調整によって柔軟なコスト管理が実現できます。 また、事前にウェアハウスを起動しキャッシュを溜めておく事で高負荷時に備える事も可能です。
以上、Lambdaを使ったSnowflakeのリサイズの事例紹介でした。